
Part 2: How to Build a Blog API using MongoDB Aggregation Pipeline Framework
Learn how to write aggregation pipeline queries through practice


Introduction
Welcome back! The first article of this series gave you a background knowledge of the MongoDB Aggregation Pipeline, its stages, operations and how it handles relationships.
In this article, we will be building a Blog API to demonstrate concepts from the previous post.
Prerequisites
A good understanding of JavaScript
A working knowledge of NodeJS
A working knowledge of MongoDB
A basic knowledge of the Command line
Overview of the Project
What is a Blog?
A blog is an online platform or website where an individual, group, or organization shares informational, educational, or personal content in the form of articles, posts, or entries.
What is an API?
API is an acronym for Application Programming Interface. API is basically a way two or more computers communicate with each other. Also, one of ways two systems can share functionalities without gaining access to the each other's entire codebases. To learn more about API, visit wikipedia.
Project Goal
Our goal is to create an API with specific endpoints that will enable a basic Blog to function effectively. This project is designed to be straightforward, ensuring that anyone who meets the requirements can easily follow through. Nevertheless, we will include features that showcase the main capabilities of the MongoDB Aggregation Pipeline. This will provide you with a deep understanding of its concepts which you can apply to create complex queries in real-life projects.
User stories

Our users are expected to achieve the above goals through the API
Designing the Structure for the Blog API
These are the endpoints we will be building in this tutorial:
| Feature | Route | HTTP Methods | Description | |
| Signup | /auth/signup | POST | POST | Register user |
| Login | /auth/login | POST | Login user | |
| Get all articles | /articles | GET | Get all articles | |
| Post article | /articles | POST | Post a new article | |
| View a specific article | /api/articles/{articleId} | GET | View a specific article | |
| Comment on article | /articles/{articleId}/comments | POST | Comment on an article | |
| View the most recent article | /api/articles/most-recent | GET | Get the most recently published article | |
| Sort article by their post date in descending order | /api/articles?sort=desc | GET | Sort article by the date they are created in descending order | |
| View the most commented article | /api/articles/most-commented | GET | Retrieve the most commented article with its comment count |
Let's get started!
Setting up the Project
In the last section, we stated the features and designed our API structure to provide our project with direction and scope. Let's set up our development environment to start building the highlighted features.
Although, I will be building this project in Visual Studio Code, feel free to use any IDE of your choice.
Initializing the project
To open VSCode on your machine, If you already have it installed, open your terminal and type the following command:
code .
Let's create our project directory and initialize npm by typing the following commands:
mkdir aggregation-pipeline-project
cd aggregation-pipeline-project
npm init -y
Next, let's create our index.js and db.js file, which are entry point and database connection file respectively:
touch index.js db.js
Creating files and directories
With the commands entered in the last step, we have created a root directory for the project. A package.json file has been generated for us by npm. Also, we created the entry point (main file) and the database connection file.
To create the subdirectories required in this project, enter the command below in order:
mkdir src
cd src
mkdir config models middlewares controllers routes utils
If you have entered above commands in order, your file structure should look exactly as below:

Now, let's create models for the project's collections:
touch models/article.js models/category.js models/comment.js models/user.js
Installing dependencies
Next, we would install these project dependencies: bcrypt, express, joi, jsonwebtoken, dotenv, pino, and express-pino-logger. Also, a development dependency called nodemon to avoid restarting our server multiple times when changes are made. Let's enter the command below to install these dependencies:
npm install jsonwebtoken dotenv mongoose express bcryptjs pino express-pino-logger
npm install nodemon -D
To configure nodemon, Open package.json file in the root directory file and enter the code below:
"scripts": {
"dev": "nodemon index.js",
"start": "node index.js"
}
Creating a Nodejs Server
In the previous sections, we have setup your entry point and database connection file. Furthermore, we created subdirectories: controllers, models, middlewares, config, services, utils and routes. Then, we created model files for our collections.
Now, let's open the index.js file in the root directory and enter the code below:
const express = require("express");
const PORT = process.env.PORT || 5000;
const app = express();
app.use(express.urlencoded({ extended: true }));
app.use(express.json());
app.get("/", (req, res) => {
res.send("Welcome to Blog API")
});
app.all("/*", (req, res, next) => {
next(new Error("Resource unavailable"));
});
app.listen(PORT, (err) => {
console.log(err || `Listening on ${PORT}`);
});
module.exports = app;
With the code above, you have setup a basic server for our application.
Now, run the command below to start the server:
npm run dev
You can test endpoints with any REST client of our choice. I'll be using Thunder client throughout this article. It's a lightweight REST API client extension available in Visual Studio Code. You can learn more about it here.
To test the server, simply make a GET request to the endpoint below from the REST client:
http://localhost:5000
This code should return this:

Hurray! Your Nodejs server is now working perfectly as expected. Now, it's time to setup database.
Setting up Database
In the previous section, we have successfully set up our Nodejs server. Now, we will be configuring the database for our project.
To interact with our database locally, we will be using MongoDB Compass. Download and install it on your local machine. If you have installed MongoDB Compass properly, the interface should look like this:
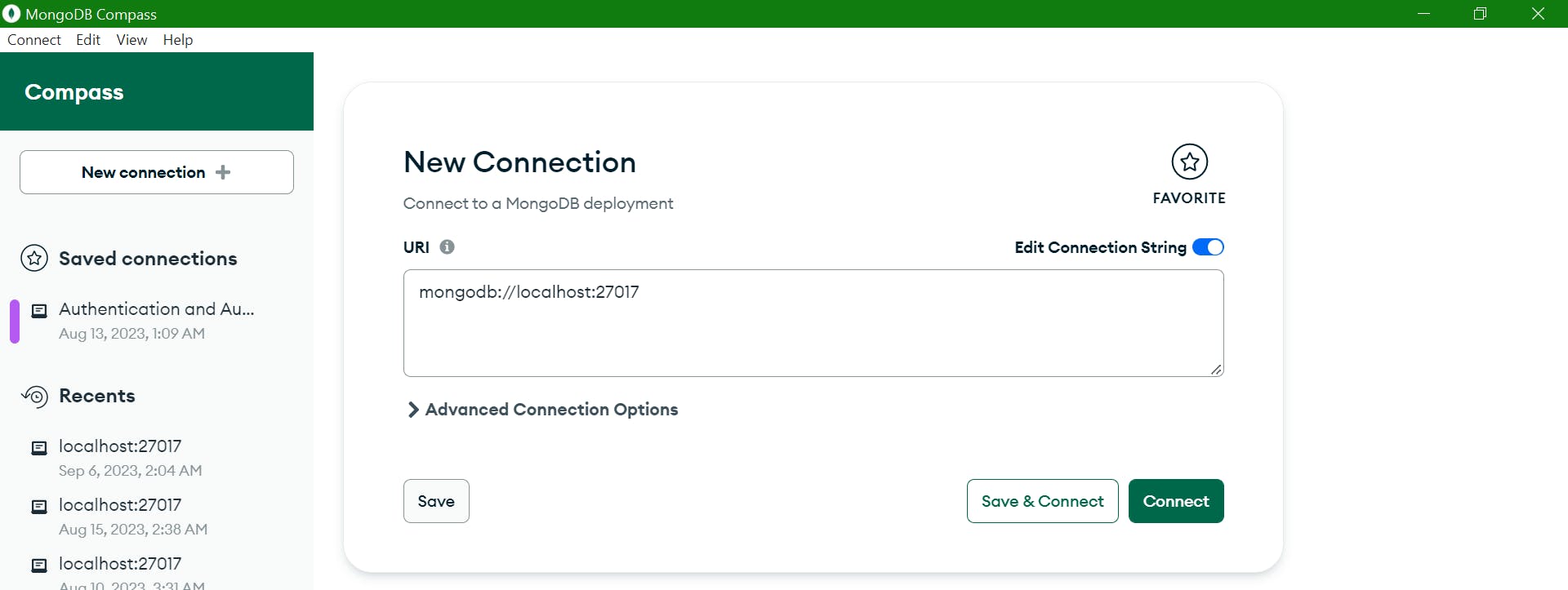
Next, click on "connect" at the top left corner and edit the connection string as shown below:
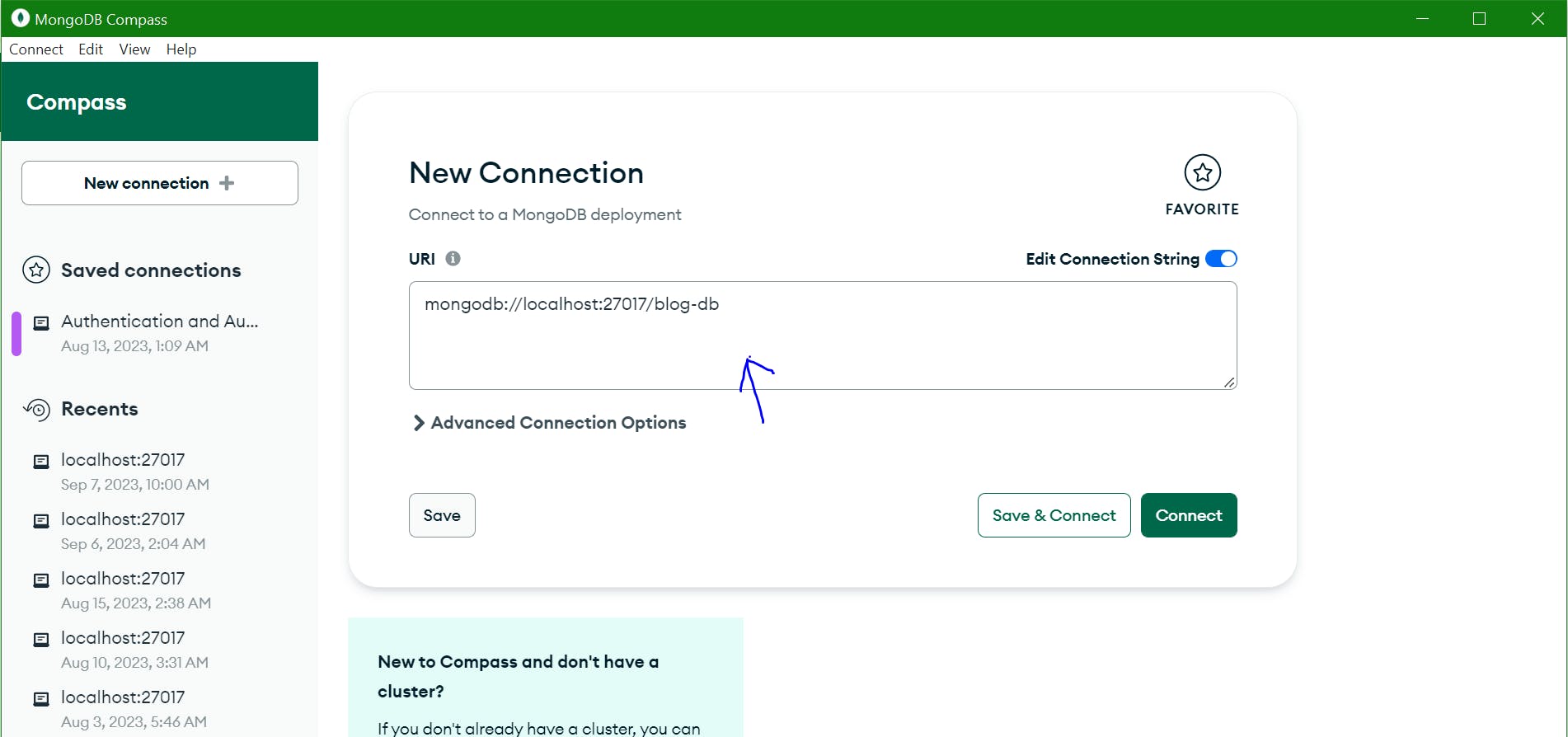
Next, click the "Connect" button to connect to the new MongoDB deployment.
In the root directory, let's create a .env file to keep the project credentials. Go to your commandline and enter the command below:
touch .env
Now, open the .env file and declare a variable to hold the connection uri
MONGO_URI=mongodb://localhost:27017/blog-db
Now that we have created a new MongoDB deployment and saved the connection string in .env file, we would enter the code below to connect to MongoDB database through mongoose. Then, open db.js and enter this code:
const mongoose = require("mongoose");
const connectDB = async () => {
try {
await mongoose.connect(process.env.MONGO_URI, {
useNewUrlParser: true,
});
console.log(`Connection to database successful`);
} catch (error) {
console.error(error.message);
process.exit(1);
}
};
module.exports = connectDB;
The code above will enable the server to connect to the MongoDB database. Now, let's call the connectDBfunction to connect to the database.
If the connection was successful, the terminal should look like this:

Implementing Features
In this section, we will start implementing our application features. In most applications, users need to register and login to perform other actions in the application. Therefore, we will be implementing the Authentication feature first.
Authentication
We will accept user information and save it in the database. Then, they will be authenticated based on the credentials when logging in.
Let's start by creating the user model:
Open models/user.js and enter the code below:
const mongoose = require("mongoose");
const userSchema = new mongoose.Schema(
{
username: { type: String, required: true, unique: true,},
email: { type: String, required: true, unique: true,},
password: { type: String, required: true },
},
{ toJSON: { virtuals: true }, toObject: { virtuals: true }, timestamps: true }
);
const User = mongoose.model("User", userSchema);
module.exports = User;
The code above will instruct MongoDB to create a user collection in our database. Notice above that we added these options:
{ toJSON: { virtuals: true }, toObject: { virtuals: true }, timestamps: true }
The above indicates that when an instance of the MongoDB model was converted to JSON and Javascript Object, the virtual properties should be included. Also, we want MongoDB to add two more fields (createdAt and updatedAt) and manage them.
Signup:
Feature Checklist:
Get user input
Validate user input
Check if user record does not exist in the system already.
Encrypt user password
Save user data in the database.
Return response
Now, let dive right in.
Create a file named auth.js in the controller directory. This file will contain our signup and login controller.
The best practice is to create separate files for each feature controller. Making each file have single responsiblity.
In ./src/controllers/auth.js enter the code below:
const bcrypt = require("bcrypt");
const User = require("../models/user");
const signup = async (req, res, next) => {
try {
//Validate user input
if (!req.body.username && !req.body.email && !req.body.password) {
res.status(400).send("Complete user information required");
}
//Check if user is an existing user
const existingUser = await User.findOne({ email: req.body.email });
if (existingUser ) {
res.status(400).send("User acount already exists.");
}
// //Hash user password
const hashedPassword = await bcrypt.hash(req.body.password, 10);
// //Save user record into the db
const newUser = await User.create({
username: req.body.username,
email: req.body.email,
password: hashedPassword,
});
let newUserObj = newUser.toObject();
const { password, id, ...rest } = newUserObj;
//Return response
return res.send({
status: "success",
user: rest
});
} catch (e) {
console.log(e.message)
}
};
module.exports = { signup };
To be able to test the signup logic, we have to create a route:
Create a new file named auth.js in the routes "./src/routes/auth.js", enter the following code:
const { signup } = require("../controllers/auth");
const router = require("express").Router();
router.post("/auth/signup", signup);
module.exports = router;
Now, let update our index.js file as shown below:
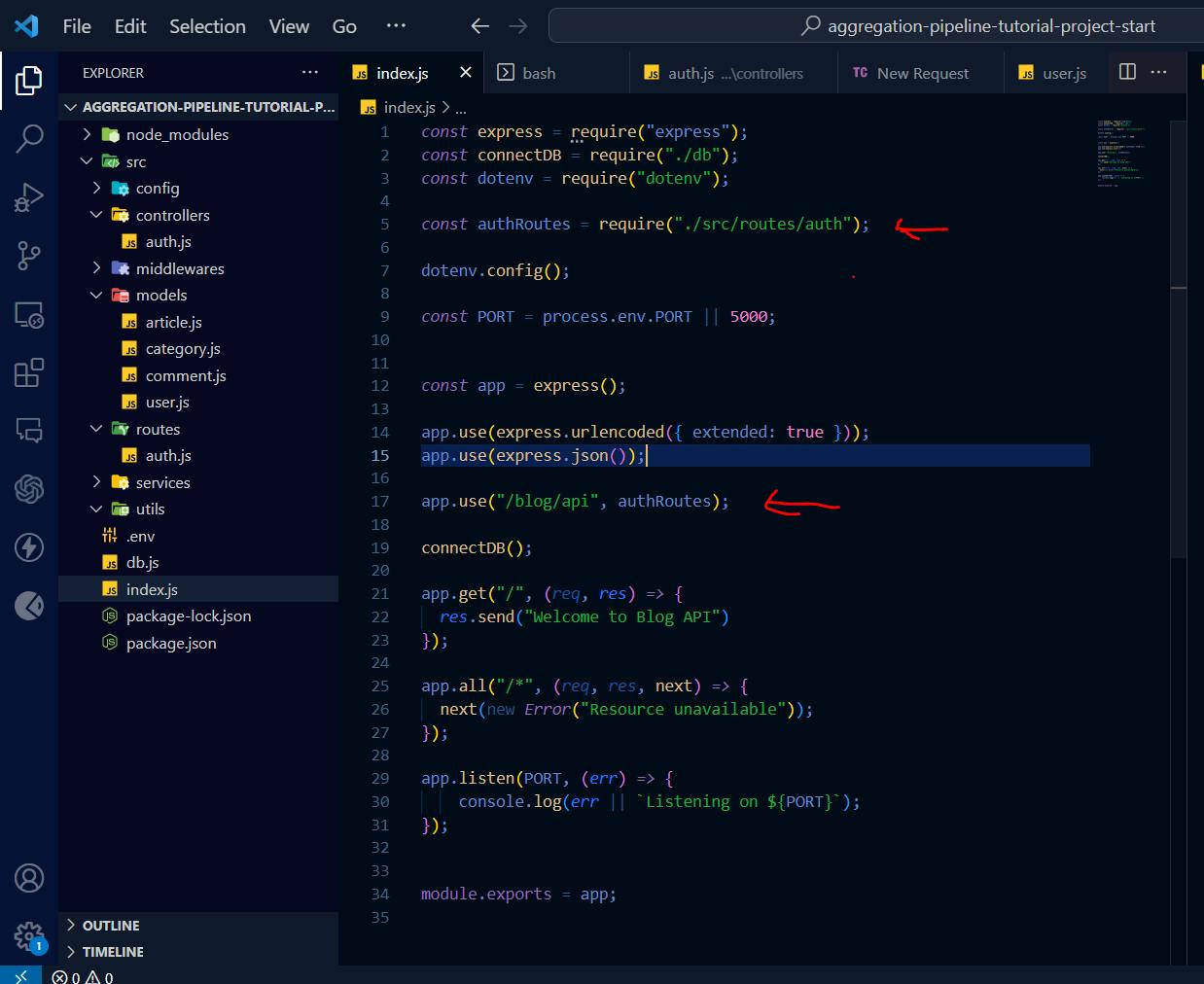
As shown above, we attached our authentication route to our application, making it possible to make request to it through the REST client.
Ensure that your server is running properly
Now, Open your REST client and make a POST request to: http://localhost:5000/blog/api/auth/signup
Also, pass this body to it:
{ "username": "temi", "email": "abc@xyz.com", "password": "abc@xyz" }
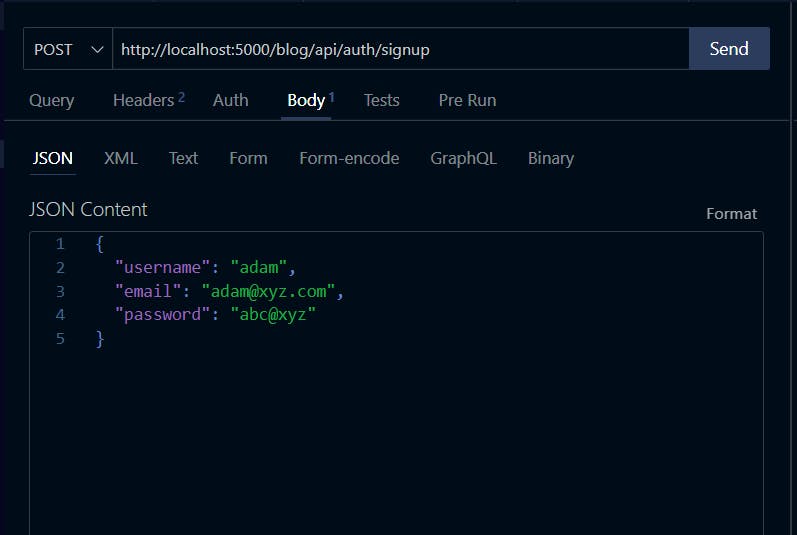
It should return this response:

It works! Now let's implement the login feature:
Login
Feature Checklist
Get user input
Validate user input
Check if user has an account in the system
Validate password
Create access token
Return response
To create the login controller, enter this code in the auth.js file:
const bcrypt = require("bcrypt");
const jwt = require("jsonwebtoken");
const User = require("../models/user");
const { listeners } = require("../..");
const signup = async (req, res, next) => {
try {
//Validate user input
if (!req.body.username && !req.body.email && !req.body.password) {
res.status(400).send("Complete user information required");
}
//Check if user is an existing user
const existingUser = await User.findOne({ email: req.body.email });
if (existingUser) {
res.status(400).send("User acount already exists.");
}
// //Hash user password
const hashedPassword = await bcrypt.hash(req.body.password, 10);
// //Save user record into the db
const newUser = await User.create({
username: req.body.username,
email: req.body.email,
password: hashedPassword,
});
let newUserObj = newUser.toObject();
const { password, id, ...rest } = newUserObj;
//Return response
return res.send({
status: "success",
user: rest,
});
} catch (e) {
console.log(e.message);
}
};
const login = async (req, res) => {
const { email, password } = req.body;
try {
//Validate user input
if (!email && !password) {
return res.status(400).send("Please enter email or password");
}
//Check if user has an account
const user = await User.findOne({ email });
console.log(user, "USER");
if (!user) return res.status(404).send("User not found");
//Check if password is valid
const isPasswordValid = await bcrypt.compare(password, user.password);
if (!isPasswordValid) res.status(401).send("Invalid password");
//Generate access token
const token = jwt.sign(
{ user_id: user._id, email },
process.env.JWT_SECRET,
{
expiresIn: "2h",
}
);
user.accessToken = token;
await user.save();
res.status(200).send({
status: "success",
accessToken: token,
});
} catch (e) {
res.send(e.message);
}
};
module.exports = { signup, login };
With the code above, we have create a login logic that'll enable our blog users login. Open ./src/routes/auth.js and enter as shown code below:
Notice that we only use access token. In real world applications, you will also require a refresh token too to generate new access token whenever it expires.

Now let's test the endpoint using your REST client. The response should look like this:
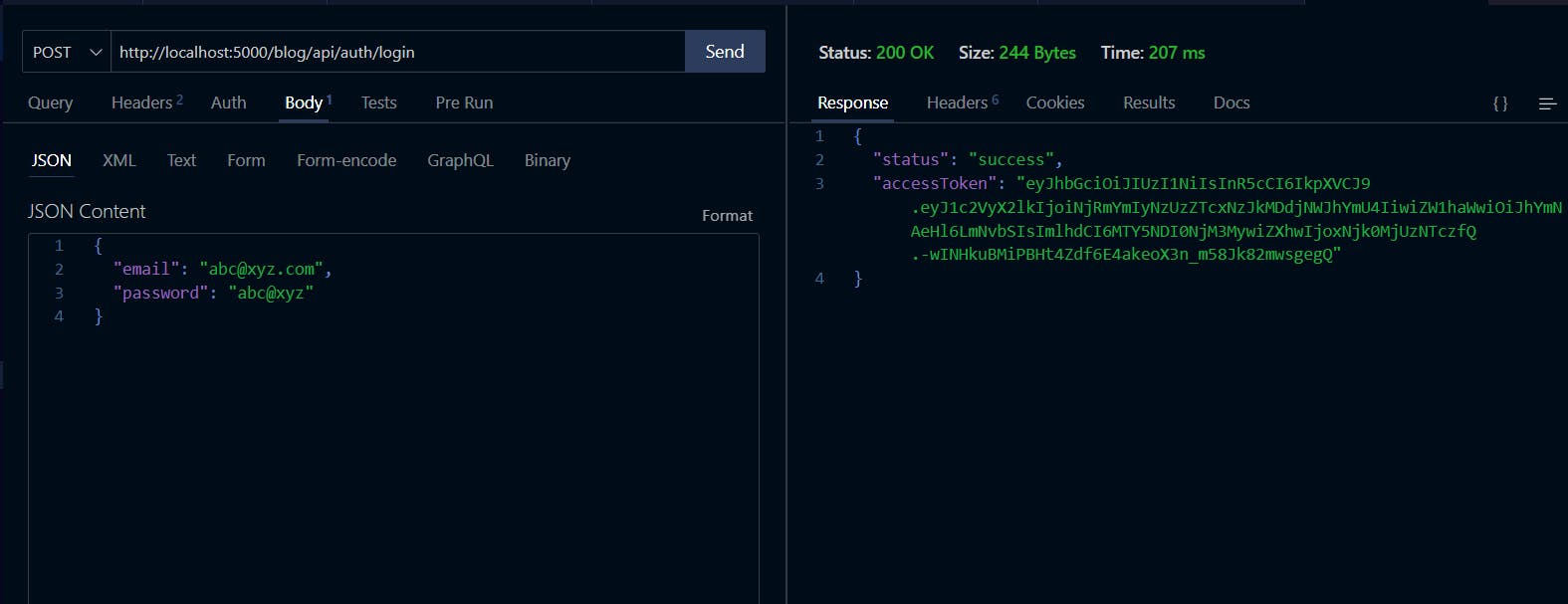
Congratulations on getting this far. Now, it's time to start building the main features of our Blog Application.
Before implementing the logic to enable user create article, we need a way of authenticating users. i.e only authenticated users should be allowed to perform other activities except the viewing articles.
Firstly, open the .env file and enter the code below:
JWT_SECRET=xx-xx-xx
Enter a secret code of your choice.
Next, create verifyToken.js in the middlewares directory. Now, open verifyToken.js and enter the code below:
const jwt = require("jsonwebtoken");
const { User } = require("../models");
const { TokenExpiredError } = jwt;
const catchError = (error, res) => {
if (error instanceof TokenExpiredError) {
return res.status(401).send({ message: "Unauthorized! Access Token has expired!" });
}
};
const verifyToken = async (req, res, next) => {
try {
const token = req.headers.authorization;
const tokenString = token.split("Bearer")[1].trim();
if (!tokenString) {
return res.status(403).send({ message: "No token in header!" });
}
const decoded = jwt.verify(tokenString, process.env.JWT_SECRET);
const user = await User.findOne({ email: decoded.email });
if (!decoded || !user) {
res.status(404).send({ message: "Invalid token!" });
}
if (user) {
req.user = user;
}
next();
} catch (error) {
return catchError(error, res);
}
};
module.exports = { verifyToken };
The code above is a middleware function to verify users to ensure that only logged in user can perform operations such as post article, update article and so on.
Post Article
This is one of the most important features of any blog application. In our blog application, we expect all users to be able to post and read articles and comments.
We wouldn't be handling roles in this application. We assume there is only one role i.e user.
Feature Checklist:
Validate user (check if they are still logged in).
Validate article title to know if nobody has posted the exact same article before.
Check if user has entered the required data.
Save article in the database
Let's start by creating our model.
Open models/article.js and enter the code below:
const mongoose = require("mongoose");
const articleSchema = new mongoose.Schema(
{
title: { type: String, required: true },
body: { type: String, required: true, },
author: { type: mongoose.Schema.Types.ObjectId, ref: "User", required: true },
category: { type: mongoose.Schema.Types.ObjectId, ref: "Category", required: true },
comments: [{ type: mongoose.Schema.Types.ObjectId, ref: "Comment" }],
upvotes: { type: mongoose.Schema.Types.Number, default: 0 },
downvotes: mongoose.Schema.Types.Number,
},
{ toJSON: { virtuals: true }, toObject: { virtuals: true }, timestamps: true }
);
const Article = mongoose.model("Article", articleSchema);
module.exports = Article;
The above code creates a schema for the article collection by defining its fields and their properties: title, body, author, category, comments, upvotes, and downvotes. The author field references a specific user in the User collection. While, the category field references a category in the Category collection. While, comments reference an array of comments in the Comment collection.
Our Article model is highly dependent on three other models (user, category and comment). We only have user model setup. Now, let's setup category and comment model. Now enter models/category.js and enter the code below:
const mongoose = require("mongoose");
const categorySchema = new mongoose.Schema(
{
name: { type: String, required: true, },
},
{ toJSON: { virtuals: true }, toObject: { virtuals: true }, timestamps: true }
);
const Category = mongoose.model("Category", categorySchema);
module.exports = Category;
Now, let's create a model for Comment collection. Comment model also has fields which reference user and article collections. Since, you have already created models for user and article. We can now create models for comment.
Comments just like article model also references two other field. So, Open models/comment.js and enter the code below:
const mongoose = require("mongoose");
const commentSchema = new mongoose.Schema(
{
content: { type: String, required: true, },
author: { type: mongoose.Schema.Types.ObjectId, ref: "User", required: true,
},
article: { type: mongoose.Schema.Types.ObjectId, ref: "Article", required: true,
},
},
{ toJSON: { virtuals: true }, toObject: { virtuals: true }, timestamps: true }
);
const Comment = mongoose.model("Comment", commentSchema);
module.exports = Comment;
In the above model declaration, the article field references a specific article in the Article collection through its _*id field. Also, the author field references a specific author in the User model through its _*id field.
Since the article model requires the category field, it'll be best for us to create a category controller first, to be able to create category. Then, we would create our article controller.
Open controllers/category.js
const Category = require("../models/category");
const createCategory = async (req, res, next) => {
const { name } = req.body;
try {
if (!name) {
return res.status(400).send("Please provide category name");
}
const categoryExist = await Category.findOne({ name: name });
if (categoryExist) {
return res.status(400).send("Category already exists");
}
const category = new Category({ name });
await category.save();
res.status(201).send({ success: true });
} catch (error) {
res.send(error);
}
};
module.exports = { createCategory };
The above code would enable us create new category.
Also, enter the code below to test the createCategory controller.
const { createCategory } = require("../controllers/category");
const router = require("express").Router();
const { verifyToken } = require("../middlewares/verifyToken");
router.post("/", verifyToken, createCategory);
module.exports = router;
Note that we passed verifyToken middleware to the above request. We want only authenticated users to be able to create categories.
Also, let's modify our auth routes and create index.js too in the routes directory:
../routes/auth.js

../routes/index.js
Finally, go to index.js file in the root directory, update the file as shown below:

Now, make a GET request to http://localhost:5000/blog/api/categories in your REST client to create a new category. The request and response of testing the endpoint is shown below:
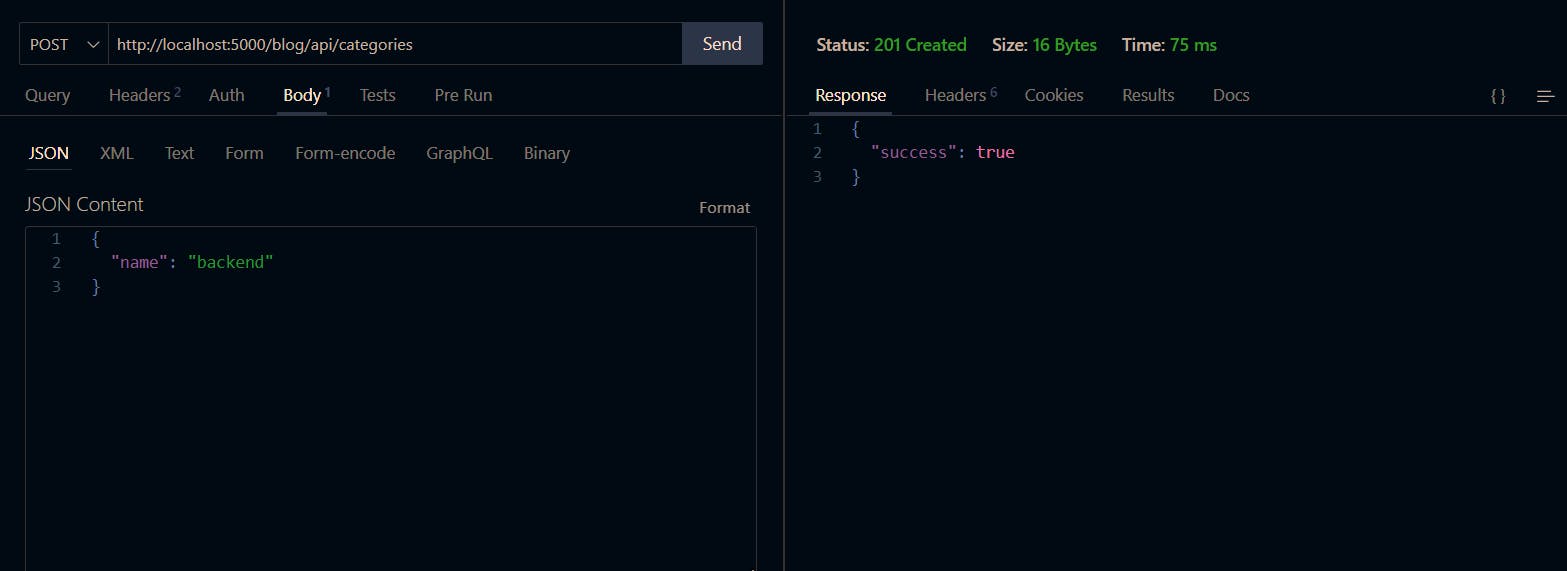
Create as many categories as much as you can for testing purposes
Now, let's create a controller to implement the logic for creating new article:
Open ../controllers/article.js too and enter the code below:
async postArticle(req, res) {
const { title, body, category, author } = req.body;
try {
//Check if user is already logged in
if (!req.user) {
throw new Error("User not found!");
}
//Check if there is no already-existing article with the provided title
const articleExist = await Article.findOne({ title: req.body.title });
if (articleExist) res.status(400).send("Article already exists");
//Check if user has filled all fields
if (!title && !body && !category && !author) {
res.status(400).send({ message: "One or more fields missing!" });
return;
}
const newArticle = new Article({
title: title,
body: body,
category: category,
author: author,
});
const data = await newArticle.save();
res.status(200).send(data);
} catch (error) {
throw new Error(error);
}
},
The code above will enable user post a new article on the blog.
To test this feature, create a file named article.js in the routes directory. We will be setting up the route for postArticle feature in it. Then open article.js and enter the code below.
const { postArticle} = require("../controllers/article");
const router = require("express").Router();
router.post("/", createArticle);
module.exports = router;
Before testing this feature, we would pass the verifyToken middleware to the postArticle route. This serves as a gatekeeper that checks if users are logged in and that their token is still valid before allowing them to post an article. Modify the code above to look like this:
const { postArticle } = require("../controllers/article");
const router = require("express").Router();
const { verifyToken } = require("../middlewares/verifyToken");
router.post("/", verifyToken, postArticle);
module.exports = router;
Now open ../routes/index.js and modify the code to look like this:
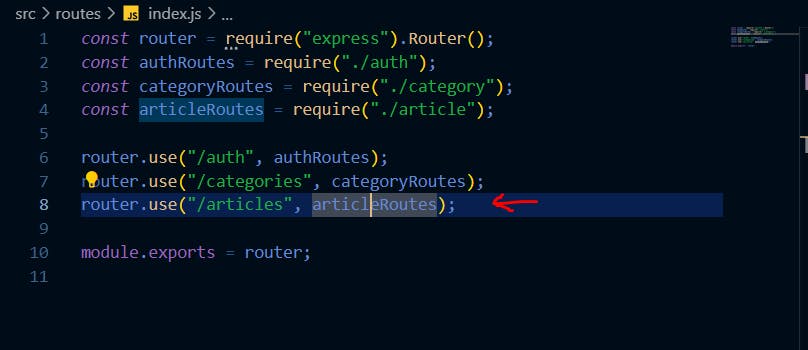
Ensure you pass the access token returned when you logged in to the request header before making the request.
Now, its time to test our new endpoint. Open your REST client and make a POST request as shown below:
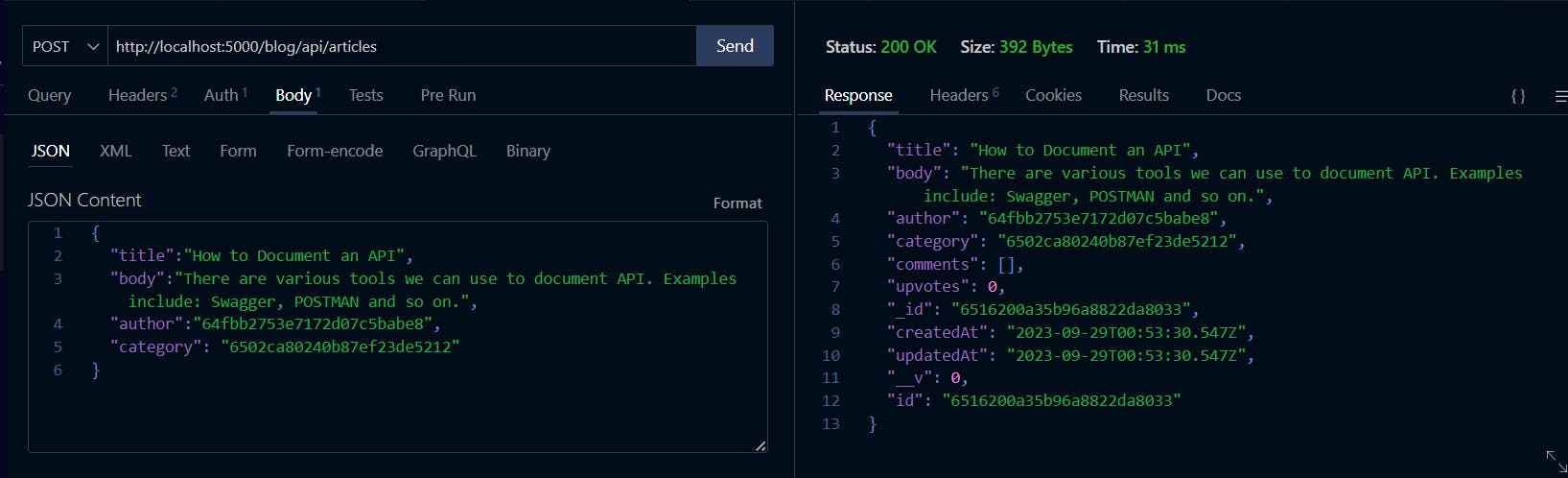
Awesome! We can now post articles on our blog.
Next, Let's build the feature to view an article.
Read an Article
With the exception of a few cases where regular users are restricted from accessing specific premium contents on sites like Medium, all users should be able to read articles on blogs. Therefore, we will develop a feature that allows users to view a specific article.
Feature Checklist:
Match article Id extracted from query parameter with the article id's in the database to check for its existence.
If its exists, return the article. Else, return an error.
Now, open the ../controllers/article.js and enter the code below:
async getArticleById(req, res) {
try {
const article = await Article.aggregate([
{
$match: {
_id: new mongoose.Types.ObjectId(String(req.params.articleId)),
},
},
]);
if (!article) return res.status(404).send("Article not found!");
return res.status(200).send({
status: true,
article,
});
} catch (error) {
throw new Error(error || "Article not found");
}
},
The code above returns an article by matching the articleId provided by the user through the query parameter with the article ids in the database.
Why did we use $match here instead of a simple Mongoose findOne function?
$match, gives us the flexibility of attaching more stages. Therefore, we won't have to write separate queries to match, join and group our data. We only write only one query. Whereas, findOne on the other hand doesn't offer this kind of flexibility.
Next, open ../routes/article.js and modify it as shown below:

Now, open your REST client and test the new feature as shown below:
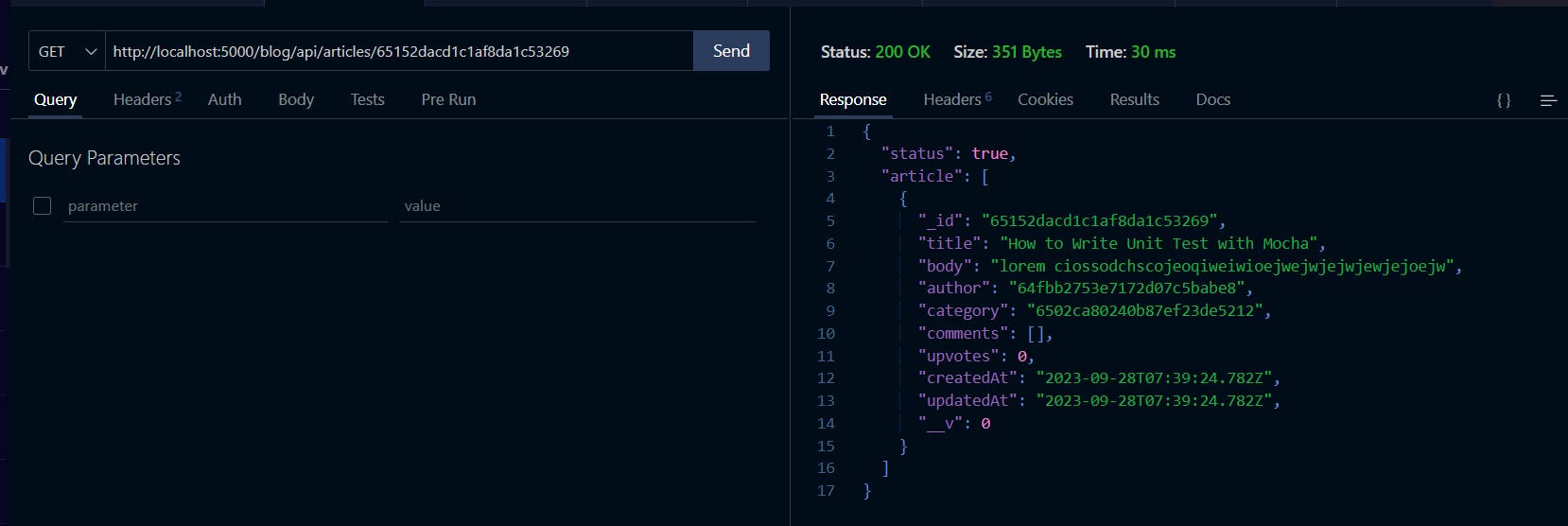
Awesome! We can now get each article by its ID field. But, we still need to modify our query to make it return a more comprehensive author data. Instead of just the author's id. Same for the category and comment fields. For now, we'll focus on populating the author and category information.
To achieve this, we need a way to relate the collections involved (user, article and category). Then we can populate the author information for each article. We will relate the article and user collection by declaring the $lookup stage and passing it to the $match stage.
const article = await Article.aggregate([
{
$match: {
_id:new mongoose.Types.ObjectId(req.params.articleId),
},
},
{
$lookup: {
from: "users",
let: { authorId: "$author"}
}
}
]);
In the code above, we defined the collection we are fetching data from using the "from" property. Next, we declared the authorId variable using "let" to store the value of the author field.
To learn more about $lookup, check the first article in this series.
Next, we create a subpipeline using the pipeline keyword to specify an array of aggregation stages. The pipeline field is not a required field for the $lookup stage. We used it to transform user collection documents before joining.
The first stage in this array is to match the authorIdof the current collection (article) with the user collection's _id field using the code below.
[{
$match: {
$expr: { $eq: ["$_id", "$$authorId"] },
},
}]
This query instructs MongoDB to check through the user collection for the user with the specified _id.
We used $expr to define aggregation expressions. And $eq to specify equality expression.
We used $$ to refer to the authorId field that we declared in the let field of the $lookup stage. This notation helps to distinguish between regular fields and variables within the context of the aggregation pipeline.
Also, we need to add the "as" field to specify our desired name for the array returned as a result of the $lookup. This field is strictly required. Without it, MongoDB will throw an error. Add the "as" field to the query as shown below:
{
$lookup: {
from: "users",
let: { authorId: "$author" },
pipeline: [
{
$match: {
$expr: { $eq: ["$_id", "$$authorId"] },
},
},
],
as: "author", //Specifies the name of the resulting object
},
}
The modified version of the getArticleById controller should look like this:
async getArticleById(req, res) {
try {
const article = await Article.aggregate([
{
$match: {
_id: new mongoose.Types.ObjectId(req.params.articleId),
},
},
{
$lookup: {
from: "users",
let: { authorId: "$author" },
pipeline: [
{
$match: {
$expr: { $eq: ["$_id", "$$authorId"] },
},
},
],
as: "author",
},
}
]);
if (!article) throw new Error("Article not found");
return res.status(200).send({
status: true,
article,
});
} catch (error) {
throw new Error(error || "Article not found");
}
},
Now, let's test to see if our code works. Open your REST client and make a request as shown below.

Awesome! Our code works. But, there is a little problem. Our query populated the entire author data, including the password field. Also, it returned user data as an array. The data has to be looped through from the client to extract the user information. This could hurt our performance. We'll be fixing these next.
How can you solve these problems?
Firstly, we should extract only the needed data from the user's object instead of the entire fields. To achieve this, we would introduce the $project stage to our sub-pipeline to specify only fields we want to return. Let's implement the $project stage as shown below:
{
$lookup: {
from: "users",
let: { authorId: "$author" },
pipeline: [
{
$match: {
$expr: { $eq: ["$_id", "$$authorId"] },
},
},
{
$project: {
_id: 1,
username: 1,
},
},
],
as: "author",
},
},
To learn about the
$projectstage, refer to the first article of this series
Re-test the endpoint as shown below:

We have successfully extracted only fields we needed from the author information.
Next, we will transform the author field into an object. To turn the author field into an object, we will use $unwind stage of the aggregation pipeline.
Note that we didn't use
$unwindstage in the subpipeline. The$unwindstage is not added to the subpipeline of$lookupbecause it is a separate stage that comes after the$lookupstage in the aggregation pipeline. It is used to transform the data structure after the join has been performed.
Modify the query to add the $unwind stage as shown below:
async getArticleById(req, res) {
try {
const article = await Article.aggregate([
{
$match: {
_id: new mongoose.Types.ObjectId(req.params.articleId),
},
},
{
$lookup: {
from: "users",
let: { authorId: "$author" },
pipeline: [
{
$match: {
$expr: { $eq: ["$_id", "$$authorId"] },
},
},
],
as: "author",
},
},
{
$unwind: "$author",
}
]);
if (!article) throw new Error("Article not found");
return res.status(200).send({
status: true,
article,
});
} catch (error) {
throw new Error(error || "Article not found");
}
},
Now open your REST client to test the endpoint as shown below:

Good! It works.
To populate the category information into each article, we will follow the exact approach used when populating the author's information. Add the code below to the existing query as shown below:
{
$lookup: {
from: "categories",
localField: "category",
foreignField: "_id",
as: "category",
pipeline: [
{
$project: {
_id: 1,
name: 1,
},
},
],
},
},
}
The code above populates only the required fields of category collection. Now, test the code as shown below:

Awesome! We have successfully implemented a feature to allow our users to view specific article with its author and category information.
Comment on Article
In the last section, we have successfully implemented the feature to fetch an article with its author and category information. But, we still need to populate comments associated with each article.
In this section, we will be implementing the endpoint to allow users comment on specific article.
Feature Checklist:
Check if author id is valid
Check if article id is valid
Check if comment's content is not empty
Save comment
Firstly, create comment.js file in controllers directory and enter the code below:
const Comment = require("../models/comment");
const Article = require("../models/article");
const User = require("../models/comment");
const { default: mongoose } = require("mongoose");
const createComment = async (req, res, next) => {
const { content, article } = req.body;
const { email } = req.user;
try {
const isAuthorValid = await User.aggregate([
{
$match: { email: String(email) },
},
]);
if (!isAuthorValid) {
return res.status(404).send("Author not found");
}
if (!content) {
return res.status(400).send("Content cannot be empty");
}
const isArticleExist = await Article.findOne({ _id: article });
if (!isArticleExist) {
return res.status(400).send("Invalid article provided");
}
const newComment = await Comment.create({
article,
author: req.user._id,
content,
});
return res.status(201).send({ comment: newComment, success: true });
} catch (error) {
throw new Error(error);
}
};
module.exports = { createComment };
Now, navigate to routes directory and create comment.js. Then enter the code below:
const { createComment } = require("../controllers/comment");
const router = require("express").Router();
const { verifyToken } = require("../middlewares/verifyToken");
router.post("/", verifyToken, createComment);
module.exports = router;
Now modify ../routes/index.js file to look like this:

You can now test the new functionality. Open your REST client and make a request to the defined endpoint as shown below:

Awesome, our users can now comment on a specific article.
Now, let's write the logic to populate the comments array in our article object.
Open ../controllers/article.js. Navigate to getArticleById function, After the { $unwind: "$category" }, add the code below:
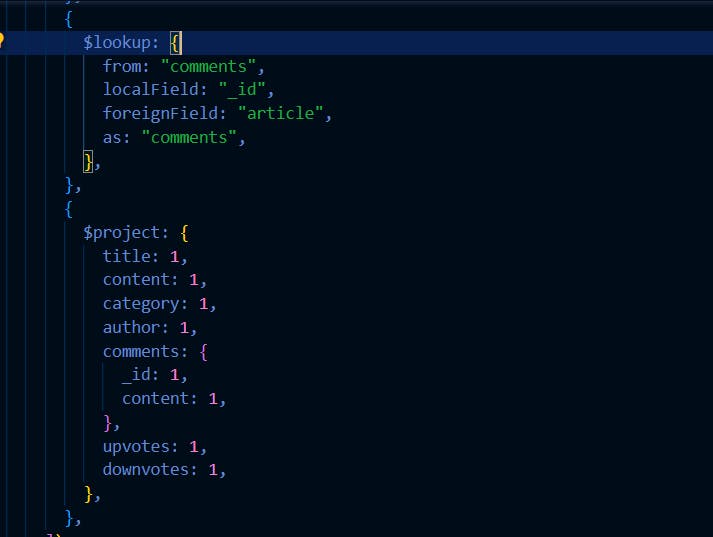
We use the code above to populate an array of comments in our article by introducing another $lookup stage . Also, we used $project stage to specify the structure of the resulting article object.
Now, open your REST client and test the endpoint as shown below:
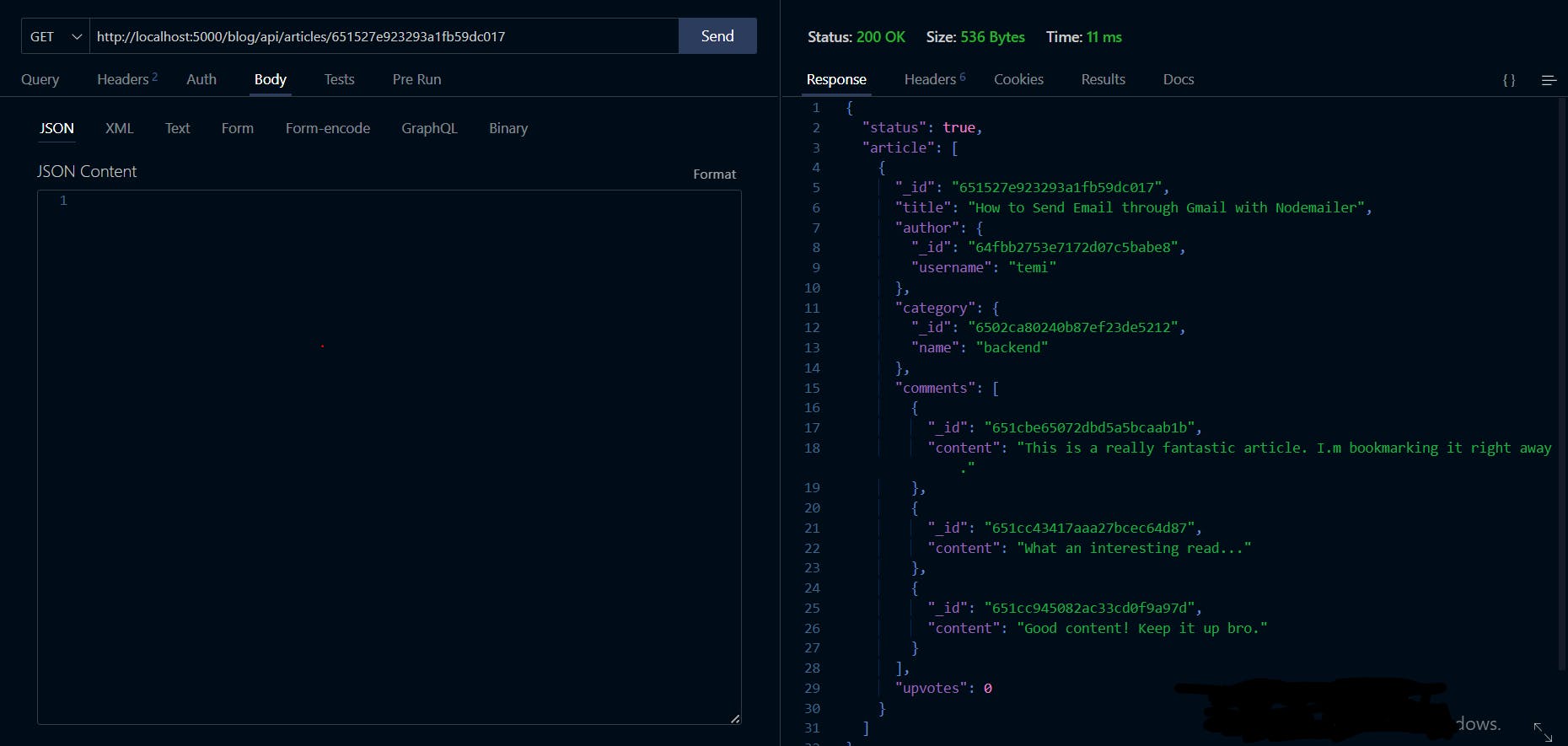
Cool! That works too.
View All Articles
Access to all blog posts is one of the most critical features of any Blog API. Users shouldn't see a complete blog post with its comments until they click on the article to read it.
Feature Checklist
Check whether there are already existing articles.
Implement a logic that provides appropriate responses when no article exists.
Write a query to retrieve all articles.
Return data with response message
Now, let's get started
Open ../controllers/article.js and create a new controller function named "getAllArticles" and enter the code below:
async getAllArticles(req, res) {
try {
// Retrieve all articles
const allArticles = await Article.aggregate([
{
$match: {},
},
{
$lookup: {
from: "users",
let: { authorId: "$author" },
pipeline: [
{
$match: {
$expr: { $eq: ["$_id", "$$authorId"] },
},
},
{
$project: {
_id: 1,
username: 1,
},
},
],
as: "author",
},
},
{
$unwind: "$author",
},
{
$lookup: {
from: "categories",
localField: "category",
foreignField: "_id",
as: "category",
pipeline: [
{
$project: {
_id: 1,
name: 1,
},
},
],
},
},
{
$unwind: "$category",
},
]);
//Check if there are existing articles
if (allArticles.length.length === 0) {
return res.status(404).send({
status: false,
message: "No article found!",
});
}
console.log(allArticles);
return res.status(200).send({ status: true, articles: allArticles });
} catch (error) {
throw new Error(error.message);
}
},
The code above retrieves all articles through a query. And if there are no existing articles, a suitable response will returned.
Note: We do not have to use aggregation pipeline for all scanerios, the find() method of mongoose could have return all articles. But, we needed to populate other information (author and user) through the same query, using $match became inevitable.
Also, open ../routes/article.js and define a route to make GET request to retrieve all articles as shown below:

Open your REST client and make a GET request to http://localhost:5000/blog/api/articles to this feature as shown below:
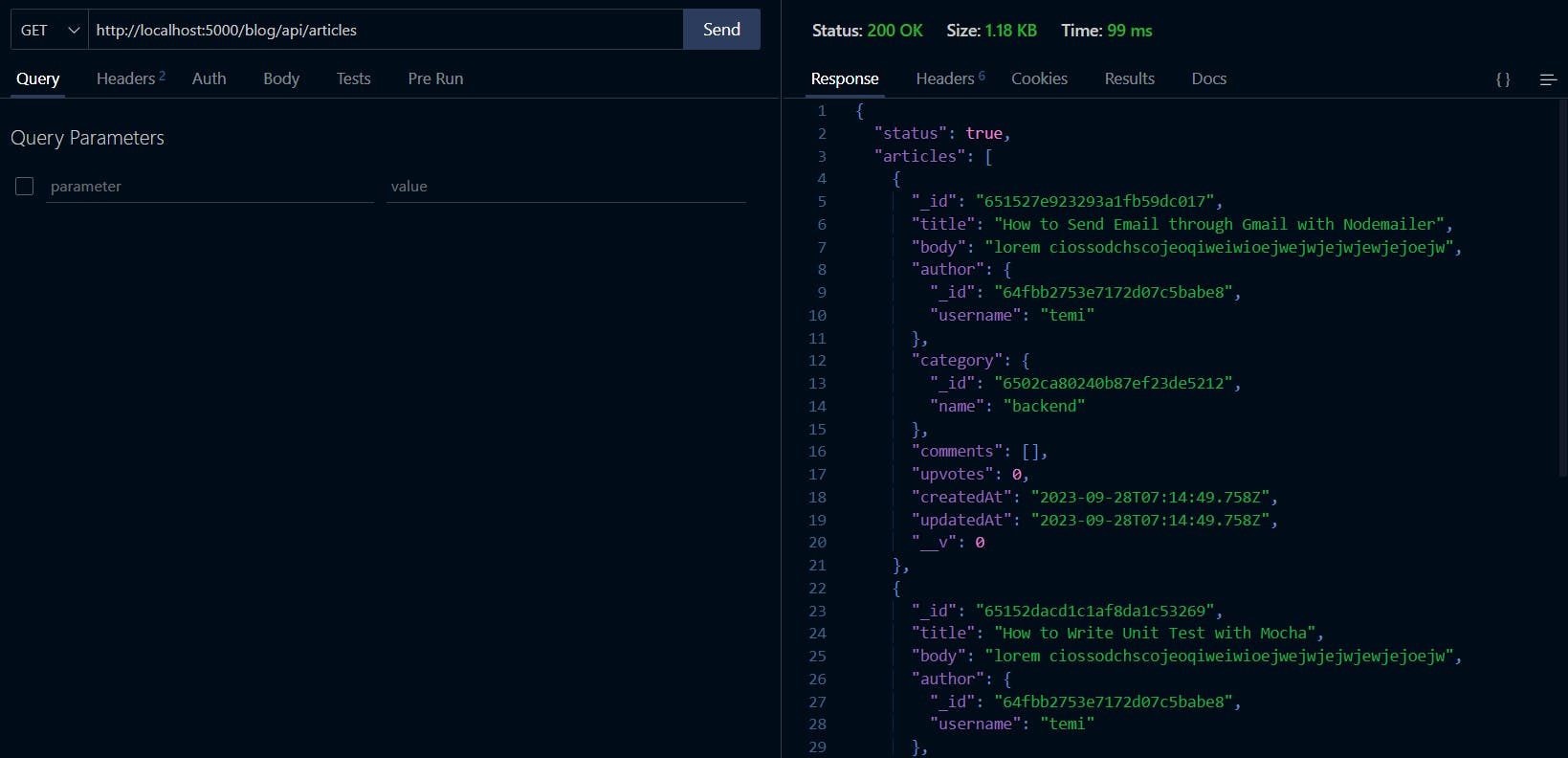
Cool! Our users can now view all articles on our blog. Before we implement the next feature, let's group our articles by their category. To achieve that, modify "getAllArticles" controller function by adding the code following after { $unwind: "$category" }
{
$group: {
_id: "$category._id",
category: { $first: "$category.name" },
articleCount: { $sum: 1 },
articles: { $push: "$$ROOT" },
},
},
Your "getAllArticles" controller should now look like this:
async getAllArticles(req, res) {
try {
// Retrieve all articles
const allArticles = await Article.aggregate([
{
$match: {},
},
{
$lookup: {
from: "users",
let: { authorId: "$author" },
pipeline: [
{
$match: {
$expr: { $eq: ["$_id", "$$authorId"] },
},
},
{
$project: {
_id: 1,
username: 1,
},
},
],
as: "author",
},
},
{
$unwind: "$author",
},
{
$lookup: {
from: "categories",
localField: "category",
foreignField: "_id",
as: "category",
pipeline: [
{
$project: {
_id: 1,
name: 1,
},
},
],
},
},
{
$unwind: "$category",
},
{
$group: {
_id: "$category._id",
category: { $first: "$category.name" },
articleCount: { $sum: 1 },
articles: { $push: "$$ROOT" },
},
},
]);
//Check if there are existing articles
if (allArticles.length.length === 0) {
return res.status(404).send({
status: false,
message: "No article was found!",
});
}
console.log(allArticles);
return res.status(200).send({ status: true, data: allArticles });
} catch (error) {
throw new Error(error.message);
}
},
The code above should return data containing categories of articles. Open your REST client to test this feature:

View Most Recent Article
This feature will enable users to view the most recent article.
Feature checklist
Fetch and count the number of articles in the database.
Check if there is article in the database.
Write a query to get the latest article in the database.
Return data
Now open ../controllers/article.js and enter the code below:
async getMostRecentArticle(req, res) {
try {
const articles = await Article.find();
if (articles.length === 0)
return res.status(404).send("No article found!");
const article = await Article.aggregate([
{
$sort: {
createdAt: -1,
},
},
{
$limit: 1,
},
]);
return res.status(200).send({ status: true, article: article });
} catch (e) {
throw new Error(e.message);
}
},
To retrieve the latest article from the database, we used an aggregation pipeline query with two stages - $sort and $limit. Firstly, the articles were sorted in descending order based on the createdAt field by using the $sort stage with a -1 value.
While this approach works, it may be considered an overkill for a simple task like this. Instead, the findOne method of Mongoose can be used to achieve the same result. The aggregation pipeline framework should be reserved for more complex tasks. The code above is provided as a proof of concept to demonstrate how $sort and $limit work.
Next, open .../routes/article.js and add a new route as follows:

Now, open your REST client to test the new feature as shown below:
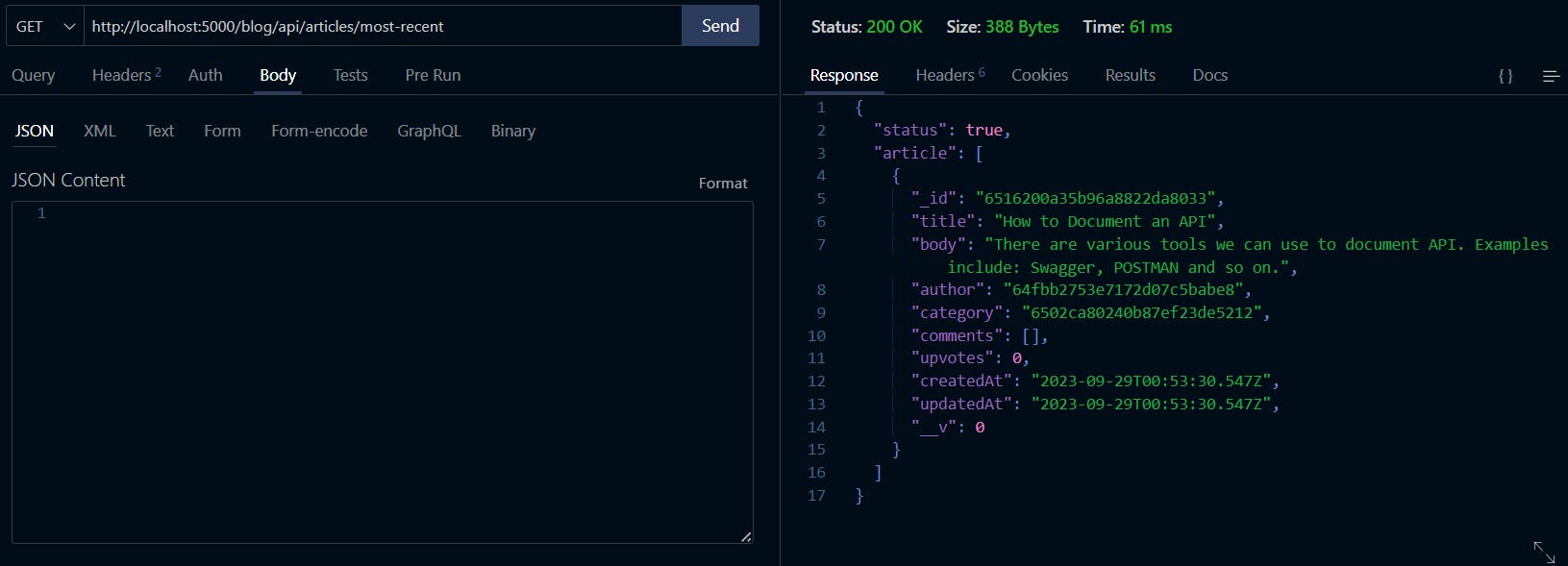
Hurray!! It works.
Congratulations! You now have a good understanding of how you can use stages and operations of aggregation pipeline framework in real-world applications.
Conclusion
Throughout this article, we have demonstrated how to utilize the powerful capabilities of the MongoDB Aggregation Pipeline framework to create various features of a blog application. By following this guide, you have learned about some of the most essential stages and operations of the aggregation pipeline framework, including $match, $lookup, $group, $sort, $limit, $project, $unwind, and $expr. Although this article does not cover all of the aggregation pipeline stages and operations, it provides a solid foundation that will allow you to be more productive when working on future MongoDB projects.
Next Steps
Remember the popular saying "practice makes perfect". You have to practice to have an absolute understanding of the concepts. I could not build the last three features I mentioned due to the size of the article.
Attempt these features:
Limit the results to a specific number of articles
Retrieve the most commented articles.
Retrieve articles with their comment count.
Also, try out whatever other features you can think of. Let me know what you can learn in the comment section below. I look forward to hearing from you soon. Until the next article, take care.
References:
https://temiogundeji.hashnode.dev/part-1-introduction-to-mongodb-aggregation-pipeline
https://www.mongodb.com/docs/manual/core/aggregation-pipeline/
https://studio3t.com/knowledge-base/articles/mongodb-aggregation-framework/
https://www.digitalocean.com/community/tutorials/how-to-use-aggregations-in-mongodb