


This article gives a detailed explanation on http, why you should understand it and how important it is in web development.
Introduction
HTTP (Hypertext Transfer Protocol) is the protocol that powers web communication and serves as the backbone of information exchange on the Internet. In this article, we explore the fundamentals of HTTP, its role in web development, and its significance in facilitating seamless interactions between clients and servers. Also, we dive deep into HTTP requests and responses, and the components of each that makes it essential in web development.
Who is this article for?
This article is for readers at all levels who want to have an intricate understanding of HTTP.
Prerequisites:
An ability to comprehend English writing.
A basic understanding of the world wide web and the Internet.
Learning Objectives:
At the end of this article, you will:
Understand what HTTP is
Understand the characteristics of HTTP
Understand the importance of HTTP
Understand how HTTP works
Understand HTTP functions that make it essential in web development
Understand the Anatomy of an HTTP request and Response
Gain a deep understanding of HTTP status codes and their importance in troubleshooting problems in web applications.
Definition of HTTP
HTTP is an Application-Layer protocol that enables the communication between clients and servers. It is the foundation of data exchange on the World Wide Web, enabling the retrieval and delivery of resources such as HTML pages, images, videos, and more between clients and servers.
Characteristics of HTTP:
HTTP (Hypertext Transfer Protocol) exhibits several key characteristics:
Stateless: It is stateless, so it doesn't keep track of past requests or sessions. The server also doesn't store client-specific information between requests. Cookies and session tokens are used to maintain the state instead.
Connectionless: It is connectionless. Each request-response exchange is a separate transaction, and once the response is delivered, the client-server connection is closed. This allows for efficient resource allocation on servers.
Text-Based: It is a text-based protocol, where messages exchanged between clients and servers are in human-readable format. Both requests and responses consist of plain text lines containing headers, status codes, and optional message bodies. This text-based nature makes it easy to read and debug HTTP traffic.
Extensible: It is an extensible protocol, allowing for the development of additional features and protocols built upon its foundation. It supports the addition of custom headers, methods, and protocols to cater to specific requirements or enhance functionality. This extensibility has facilitated the growth of web technologies and APIs built on top of HTTP.
Flexible Content Handling: It can handle various types of content, including HTML pages, images, documents, videos, and more. It supports content negotiation, allowing clients and servers to agree on the most appropriate representation of a resource based on factors such as content type, language, or encoding.
Uniform Resource Identifiers (URIs): Uses URIs to identify and locate web resources. URIs (It identifies a resource and differentiates it from others by using a name, location, or both.) specify the address and path to a specific resource on the web. They provide a standardized way to reference and access resources across different web platforms.
Scalability: It is designed to be scalable, allowing for a large number of clients to interact with servers concurrently. It supports parallel processing of multiple requests and responses, enabling efficient handling of high-traffic loads.
Caching: It includes mechanisms for caching resources, allowing clients to store copies of resources locally. Caching reduces the need for repeated requests to the server, thereby improving the performance of web applications and reducing network traffic.
These characteristics make HTTP a versatile and widely adopted protocol for web communication, enabling the retrieval, delivery, and exchange of resources over the Internet.
Importance of HTTP
How HTTP works can be likened to sending a letter through a postal worker. It's like putting a letter in an envelope with the recipient's address written on it. The envelope represents the HTTP protocol, a set of rules for transmitting information over the Internet. Just as a postal worker reads the destination address and delivers the letter, web browsers and servers handle HTTP requests and responses, acting as the digital equivalent of postal workers. The internet serves as the network infrastructure, similar to the postal system, enabling the transmission of information between computers. HTTP facilitates the proper addressing, delivery, and understanding of data, making clients request resources from servers and receive appropriate responses.

Therefore, HTTP is pivotal in facilitating web communication and enables clients to request and receive web resources from servers. Its standardised nature, request-response cycle, extensibility, and the introduction of HTTPS make it a fundamental protocol for web browsing, application development and secure online interactions.
Functions of HTTP
So far, we have looked at what HTTP is and why it is essential. Next, we will be exploring some of its functions that makes it essential in web development.
HTTP (Hypertext Transfer Protocol) performs several important functions in web communication:
Resource Retrieval: It allows clients (such as web browsers) to retrieve resources from web servers. Clients send HTTP requests to servers, specifying the desired resource's URL (Uniform Resource Locator). The server processes the request and returns the requested resource by the client, such as a web page, image, document, or video to it. To learn about HTTP, yfirst had to arrive at this page by either making an HTTP request to Google which returns a myriad of results or getting redirected from a website or making an HTTP through your browser to this site directly. And then you get served an HTML page by the server when you click on the link to this article.
Client-Server Communication: It enables communication between clients and servers in a client-server architecture. Clients initiate requests to servers, and servers respond with the requested resources accompanied by the appropriate status codes indicating the status of the request. This communication allows the exchange of data and information over the internet.
Provision of Request Methods: It provides various request methods, also known as HTTP verbs, to perform different actions on resources. Common methods include:
GET: Retrieves a resource from the server.
POST: Submits data to the server, typically to create or update a resource.
PUT: Updates or replaces a resource on the server.
DELETE: Deletes a resource from the server.
HEAD: Retrieves only the headers of a resource, without the message body.
More details on HTTP methods will be provided in the later part of the article.
Specification of Request and Response Information: HTTP headers carry additional information and instructions in both requests and responses. Headers providing metadata about the content type, caching directives, authentication details, cookies, and more. They enable customization, control, and optimization of the communication process between clients and servers.
Indication of Request Status Through Status Codes: HTTP status codes are three-digit numbers returned by servers in response to client requests. These codes indicate the outcome of the request and provide information about whether the request was successful, encountered an error, or requires further action. Common status codes include 200 (OK), 404 (Not Found), 500 (Internal Server Error), and more.
Identification and Location of Web Resources Through URLs: URLs (Uniform Resource Locators) are used in HTTP to identify and locate web resources. A URL consists of the protocol (e.g., "http://" or "https://"), domain name, port number, path, and optional query parameters. URLs serve as addresses for accessing specific resources on the web.
Content Negotiation: It supports content negotiation, allowing clients and servers to agree on the most appropriate representation of a resource based on factors such as content type, language, or encoding. This flexibility allows for delivering customized content to clients based on their preferences and capabilities.
These functions collectively enable the retrieval, delivery, and exchange of resources over the internet, forming the foundation of web communication and powering various web applications, APIs, and services.
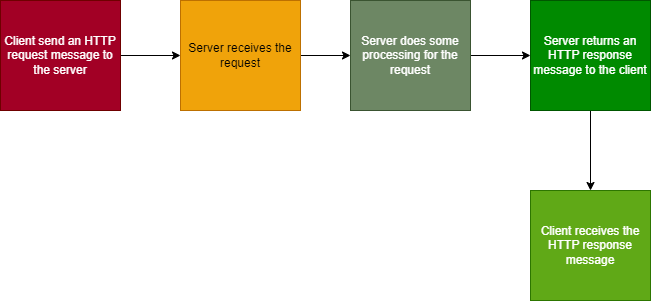
How HTTP Works
HTTP works through a mechanism called HTTP messages. There are two types of HTTP messages:
Request: They are messages sent by clients to the server to trigger an action.
Response: They are messages sent to the client by the server in response to the request made by the client.
Client-Server Model
HTTP Request Messages
HTTP request is composed of three different components:
An HTTP client sends an HTTP request to a server in the form of a request message which includes the following format:
Request Line:
A request line contains three components:
HTTP method to be used.
URI of the requests.
HTTP protocols version to be used.
They have this structure:
HTTP-method URI HTTP protocol.
For now, just know that the HTTP method specifies the kind of action the user wants to perform. Actions include: Reading a resource, updating a resource, storing a resource or deleting it on the server. We will discuss the HTTP method in great detail in the later part of this article. The URI refers to the address where the resource is located on the server, it is also known as the request target. HTTP protocol refers to the version of the HTTP protocol to be used. E.g. HTTP/1.1, HTTP/2.0 revision. A typical Request line looks like the below:
POST /API/books HTTP/1.1
The above request line simply shows that a client wants to send data to the server.
- A set of header fields are simply metadata sent with a request to provide information about the request. Each header is specified using this format.
Connection: Keep-Alive.
The two examples (Host and Connection) above are some of the important request headers that should be used in our HTTP requests. Also, we can introduce our headers too.
- A body (optional): The request body is where we put additional information we want to send to the server. The request body may become important depending on the kind of request method we want to use. When making a POST request (using the POST method in a request), the body is important as it indicates the data we are trying to send to the server. However, the GET request does not require a body. We do not want to send complex information to the server when trying to get data from it. A typical request body for a POST request would look like this:
{
username: “adam”,
password: “123”
}
That said, an HTTP request with three parts looks like this:
POST /API/books HTTP/1.1
Host: api.myapp.com
Content-Type: application/json
Cache-Control: no-cache
{
"title": "The nice housemate",
"author": “Christopher Veebute“
}
- HTTP Request Methods:
HTTP methods (sometimes called verbs) are used to define actions that should be performed on the resource identified. What the resource represents depends on the implementation of the server. It could be a file, pre-existing data generated, or data generated as a result of executables that reside on the server. In HTTP/1.0, only GET, HEAD, and POST methods are defined in its specification. And then HTTP/1.1 comes with 5 additional methods namely: PUT, DELETE, CONNECT, OPTIONS, and TRACE methods. Method names are case-insensitive, unlike header names. Below are some of the available methods:
i. GET:
The GET method is used to retrieve data from the server without any changes to it. It is also preferred over the POST method as it can be addressed over the URL. This enables bookmarking and sharing and makes GET responses eligible for caching, which can save bandwidth.
Example use-cases for GET requests are: Getting the list of blog posts by a particular author in a blog app. Getting the list of products added to the shopping cart by a user.
ii. POST:
POST method is used when sending data to the server. Some of its use cases are file upload, form submission and so on. Every time you post a message to a forum, subscribe to a mailing list or complete an online shopping transaction. You make use of the POST method.
iii. PUT:
The PUT method asks the target resource to establish or modify its state according to the representation provided in the request. The client defines the server's target location, which sets it apart from POST. Also, it is used to update an existing resource on the server. It is typically used when the client wants to send data to the server to replace or modify an existing resource. If you retry a request numerous times, that will be equal to a single request conversion i.e. It is idempotent.
iii. PATCH:
The PATCH method makes partial modification to a target resource. It does this without completely replacing the resource. Sending the same request to a resource using patch method does not make changes to the state of the server or the resource. Unlikely PUT, which acts exactly opposite to that. To learn more about the differences between both methods
- Request Headers
Request Headers are used in HTTP requests to provide information about the HTTP requests so that the server can tailor the response accordingly. Headers are specific in their functions. For example, there is a header whose function is to supply authentication credentials. Also, Accept-* headers are used to specify the format of the response acceptable by the client. Other functions of headers are to control caching, get information about the user-agent or referrer etc. Note, some headers exist in the request header but are referred to as representation headers by the specification. An example is the popular Content-Type header. Below are some of the request headers passed with a GET request.
GET /about.html HTTP/1.1
Host: https://www.freecodecamp.org/news/about/
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html, application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US, en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://www.freecodecamp.org/news
Connection: keep-alive
Upgrade-Insecure-Requests: 1
If-Modified-Since: Mon, 18 Jul 2016 02:36:04 GMT
If-None-Match: "c561c68d0ba92bbeb8b0fff2a9199f722e3a621a"
Cache-Control: max-age=0
HTTP Response
HTTP response is how a server responds to a client's request. The response aims to provide the client with the resources it requested, send an error to the client in case an error occurs in the processing of its request, or inform the client that the action it requested has been carried out. Below is the component of an HTTP response:
A status line:
The status line is the first line in the response message. It consists of three items:
The HTTP version number shows the HTTP specification to which the server has tried to make the message comply.
A status code, which is a three-digit number indicating the result of the request.
A reason phrase, also known as status text, is human-readable text that summarizes the meaning of the status code.
The status line can be summarized below:
HTTP/1.1 200 OK
- Response Status Codes
HTTP response status codes specify whether a request is successful or not. There are classified into 5 groups:
- Informational responses (1xx):
This interim response instructs the client to proceed with the request or, if the request has already been completed, to disregard the response.
- Successful responses (2xx):
This indicates that the request made by the client to the server has been successful. Or that the server returned the right response to the client’s request. A successful response can have different meanings depending on the type of request method used. For example: for the GET request method: It means that the client has successfully fetched the requested resources from the server, for the POST method, it could mean that a resource password to the request body has been stored on the server in the DB.
- Redirection messages (3xx):
The HTTP redirection error messages are the responses that are given by the server side to guide the client to a new location by providing the URL of that specific place. These codes are returned if the request has more than one possible response.
- Client Error responses (4xx):
These are error messages that occur as a result of a client's request. It means the request contains incorrect syntax or cannot be fulfilled. It could be that the user sent too many requests in a lesser amount of time which is not in line with the server’s rate-limiting configuration, It could be as a result of the client not authenticating and many other reasons. The client error code returned by the server indicates the cause of the error.
- Server Error responses (5xx):
Server error codes are also considered errors. However, they denote that the problem is on the server’s end. This can make them more difficult to resolve.
Understanding HTTP response status codes is essential for debugging web applications and for understanding the results of HTTP queries. These codes enable developers and system administrators to quickly locate and fix problems, resulting in a smooth user experience and improved program stability.
For a more detailed explanation of the error status code, please go through these guides:
- Response Headers:
The response header is a component of a network packet sent by a server to a client in response to the request sent by the client. It is utilized in web communication to deliver web pages and other resources to clients. The information embedded with the HTTP response header includes the destination IP address, data type, host address and more. HTTP headers include the following:
Accept-RangesAgeETagLocationProxy-AuthenticateRetry-AfterServerVaryWWW-Authenticate
- Response Body:
The HTTP response body is the data that is sent from a server to a client as part of an HTTP response. It contains the content or payload that the client requested from the server. The response body can include various types of data, such as HTML, XML, JSON, images, videos, or plain text.
- Below are a few examples of HTTP response bodies:
<!DOCTYPE html>
<html>
<head>
<title>Example Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>This is an example HTML response.</p>
</body>
</html>
In this example, the response body contains an HTML document with a title, heading, and paragraph. Below is another example of a response body in json format.
- JSON Response Body:
{
"name": "John Doe",
"age": 30,
"email": "johndoe@example.com"
}
This JSON response body provides information about a person, including their name, age, and email.
- Plain Text Response Body:
This is a plain text response.
Here, the response body consists of simple plain text.
- Image Response Body:
Making a GET request to an image hosting service or cloud object storage, such as Amazon S3, Cloudinary, or Dropbox, to retrieve a specific image hosted on it would result in an image response. For example, when making a GET request to this endpoint, it returns an image hosted on Cloudinary:
(You may need to provide the actual endpoint URL for clarity or context.)
https://res.cloudinary.com/demo/image/upload/sample.jpg

In this case, the response body contains the binary data of an image file. The client can interpret this data to display the image.
- XML Response Body:
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>Jane</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget to submit the report.</body>
</note>
This XML response body represents a note with a recipient, sender, heading, and body.
These examples illustrate the variety of data that can be included in an HTTP response body, depending on the type of content requested and the server's response.
Where to go from here
Congratulations, you have gained a fundamental knowledge of HTTP, if you are keen on diving deeper into its advanced concepts. Below are a few suggestions.
The evolution of HTTP from HTTP/1.0 to HTTP/2.0
Understanding of HTTP and HTTPS.
Features of different HTTP versions such as caching, pipelining, multiplexing, header compression, stream prioritization, server push and many other features. These features bring improvements in terms of performance, efficiency, and functionality to enhance the web browsing experience. As an engineer, they will help contribute to the development of high-quality, efficient, and responsive web applications.
A. Further Reading
https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events
https://developer.mozilla.org/en-US/docs/Glossary/Proxy_server
Conclusion
In conclusion, the Hypertext Transfer Protocol (HTTP) serves as the backbone of communication on the World Wide Web, enabling the exchange of information between web browsers and servers. Throughout this article, we have explored the key aspects such as: what it’s all about, its importance, methods, request, response and so on.
It is worth noting that HTTP is not static but continually evolving. As new challenges and requirements arise, the protocol continues to be refined and enhanced. Keeping up with the latest developments and emerging standards will be essential for staying at the forefront of web development and ensuring optimal performance for users.
HTTP remains an indispensable protocol that enables seamless communication between clients and servers on the web. By understanding its features, implementing best practices, and leveraging additional tools and technologies, web developers can create faster, more efficient, and more reliable web experiences for users around the globe.